The Conversational Rollercoaster

Read the Discourse Studies paper here:
Albert, S., Albury, C., Alexander, M., Harris, M. T., Hofstetter, E., B., E. J., & Stokoe, E. (2018). The conversational rollercoaster: Conversation analysis and the public science of talk. Discourse Studies, 20(3), 397–424. https://doi.org/10.1177/1461445618754571
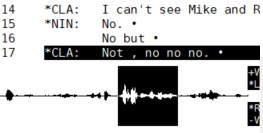
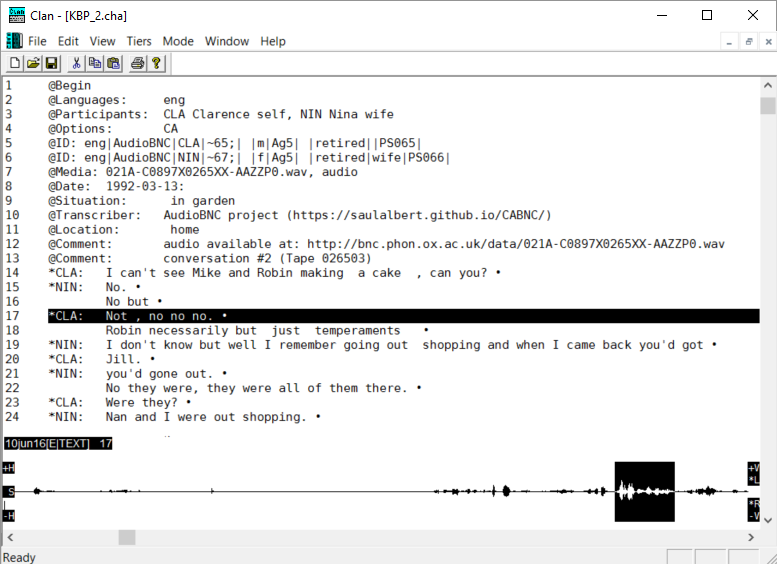
 The Conversational Rollercoaster is a new public ‘demo’ format for ethnomethodology and conversation analysis. I developed the format for New Scientist Live in collaboration with Loughborough and the CARM group in order to make it easier to explain EM/CA research in a public exhibition context. The idea is that you can take a live conversation – in this case provided by The People Speak‘s pop-up talk-show Talkaoke, and subject it to instant EM/CA analysis. What’s more, you can involve the public as analysts in a variety of activities – ‘being the data’ on the Talkaoke table, spotting interactional phenomena, gathering data, transcribing, analyzing and reporting findings on the ‘results wall’.
The Conversational Rollercoaster is a new public ‘demo’ format for ethnomethodology and conversation analysis. I developed the format for New Scientist Live in collaboration with Loughborough and the CARM group in order to make it easier to explain EM/CA research in a public exhibition context. The idea is that you can take a live conversation – in this case provided by The People Speak‘s pop-up talk-show Talkaoke, and subject it to instant EM/CA analysis. What’s more, you can involve the public as analysts in a variety of activities – ‘being the data’ on the Talkaoke table, spotting interactional phenomena, gathering data, transcribing, analyzing and reporting findings on the ‘results wall’.
Record, transcribe, analyze and report back: the conversational rollercoaster in action at #NewScientistLive @QMCogSci @lborouniversity pic.twitter.com/2pgdgtSbDl
— Saul Albert (@saul) September 24, 2016
Ann Doehring‘s very nice drawing of the process (in the tweet above) provides a useful outline of how it works – and how it can be adapted for other contexts. All the software, data, photos and other materials are available for re-use and re-development.
A full how-to blog post for those wishing to try running the format themselves will soon be available on my blog. Until then, check the blog post at https://rolsi.net/ for a description of the event.
Thanks to:
- The CogSci group at Queen Mary University of London, especially Ella Rice and the whole team at EECS.
- Charles Antaki, Bogdana Huma, Rein Skiveland, Liz Stokoe, and the CARM team from Loughborough for getting involved early on and supporting the event through to production.
- A dozen eggs for their wonderful banner/artwork (right).
- Matt Jarvis and Toby Harris for helping with the display software.
- The People Speak for getting people generating data!
- Frank Swain, Natasha Gorohova, Jacqui McCarron and the team at New Scientist Live.
- All the participating analysts: Charlotte Albury, Marc Alexander, Charles Antaki, Ann Doehring, Sam Duffy, Joe Ford, Toby Harris, Emily Hofstetter, Bogdana Huma, Alexandra Kent, John Rae, Jessica Robles, Rein Skiveland, Liz Stokoe, and Veronica Gonzalez Temer.
- Thanks also to Vanessa Clare Pope and Betül Aksu for invaluable event support.
The Conversational Rollercoaster Read More »