Sustainable Research Literature Management with Docear part I

This is part I of a two-part post in which I will walk you through some key parts of a technically-savvy user’s long-term literature review and maintenance strategy. In part I you will learn how to use Docear to:
- take notes while reading that won’t get lost or damaged by your software,
- organise notes and annotations so you won’t forget why you took them,
In part II, should you choose to get geeky and read that bit too, you will learn to:
- maintain associated bibliographical records,
- use Docear in a way that will keep your literature reviewing current for years to come.
Warning: long post, so here’s a table of contents:
Contents
Introduction
What this guide is for
There are many software systems that purport to be helpful in managing academic literature, and everyone swears by their own. My belief about software is that it’s usually a nightmare, and your choice should be driven by considerations of damage limitation. With that in mind, I am using Docear to limit the damage that software can do to my literature reviewing and thesis preparation process.
This guide will outline some ways to use this software with long-term sustainability in mind. If you don’t know what Docear is, you could spend 6 minutes watching this video.
If you’re starting a PhD or a research process, and thinking about how to keep up with the literature long-term, you might want to think about using Docear in the ways described here. To get started with that, first download and install Docear, read Docear’s own very good user guide to understand the basics, then come back and read this1.
Why Docear works for a long-term research strategy
There are lots of good reasons listed on the Docear website that compare Docear’s features to Zotero, Mendeley or other reference management systems.
My choices are driven by issues of long-term software sustainability, and focus on cross-compatibility, reliability and stability. Docear fits my criteria because:
- It’s Open Source software using well adopted, documented and supported file formats.
- Docear’s plain text-based file formats for are searchable and editable.
- Text-based files enable version control and collaboration (including with your future self).
- Docear, JabRef and FreePlane all work together or separably on most platforms.
In general, Docear conforms with the tenets of Unix Philosophy i.e.: Docear is designed to be modular, clear, simple, transparent, robust, and extensible for users and developers.
What all this means for academics is that
- You are probably always going to be able to edit and view these files on any platform.
- If you just want to change a bibliographic reference, you can just use the bibliography manager (or a text editor) to do it on any computing platform without even firing up Docear.
- If you just want to view your Docear file on Android, i0S, or using any mind-map viewer, you can open it (albeit with limited features) in FreePlane, FreeMind, Xmind or the many associated pieces of software that can read these files.
- If you want to search your entire archive of papers, you can do it using grep on a command line or with any text-search and indexing system that can read your file system (I use Recoll).
- It doesn’t mess with your files or do complex or potentially destructive things, use fancy databases etc. You can move away from Docear at any time – you’ll still have your annotations, your PDFs, your BibTeX reference files.
No vendor lock-in, no dodgy or dangerous games with your data. That’s a lot of damage-limitation right there, and this isn’t even mentioning a compelling and unusual combination of features that Docear itself documents very well – so I won’t go over those, but nonetheless, here is my list of:
Killer features of Docear
- Import annotations from PDFs, and cross-sync them (change the annotation in your PDF – it gets changed in Docear, change it in Docear, it gets synced in your PDF).
- Organise your annotations in multiple ways
- Organise your annotations visually by research theme / category / heading
- Organise your annotations visually by paper / book / author
- Mix these up, copy and paste annotations multiple times, make further notes on annotations etc.
- Import file/folder structures from your hard disk, so you can get an overview of your data, files and research materials alongside your literature, and make notes and connections between them.
- Maintain the bibliographical associations of your annotations and notes, even after copy/pasting/reorganising them.
Just to re-state this: I’m not going to go through these basics in this how-to, so if you want to learn to use Docear from scratch you really should read the manual. What follows are some adaptations I’ve made to the Docear workflow that I think make it even more useful as a secure and long-term bet for research literature management.
How to take notes that won’t get lost or corrupted
PDFs, however flawed as a document format, are a de facto standard in academia and aren’t going away soon. You can read, edit and share them relatively easily on all devices and platforms, so that’s probably how you should store your annotations and bibliographical data.
General annotation strategy
Many pieces of literature review / bibliography management / annotation software keep notes and bibliographical records scattered about in proprietary databases or separate annotation files, so following Docear’s excellent advice on the issue I use ezPDF Reader on Android, and PDF-XChange Viewer on Linux (via wine) to make my annotations in my PDFs themselves.
Docear allows you to manage these annotations effectively without sacrificing the simplicity and security of having it all in one, cross-platform, easily accessible file.
Synchronisation and backup across clients/computers
The benefits of this are clear: you can easily back up your PDFs.
I use Dropsync to synchronise my main_literature_repository folder with a folder on my Android tablet, so when I’m on the go I can take notes and have them appear automatically in my literature review mind map when I start up Docear.
I tried using Dropbox’s own android client, I found that it would sync too frequently, and sometimes randomly deletes its temporary files. For this reason I recommend syncing your entire PDF repository to your mobile devices, editing the PDF locally (on the android device’s file system), then synchronising with Dropbox or whatever local/cloud/repo/backup service you prefer.
How to remember why you took your notes in the first place
I have most of my research ideas while reading, but they’re not all just ‘notes’, they are really different in response to different ideas about what I plan to do with that idea. So I find it useful to distinguish between the kinds of notes I take on documents. When I take an annotation, I track that difference by starting the annotation with one of 10 or so labels:
- todo: The most important label – this reminds me to do something (look up a paper, change something in my manuscript etc.)
- idea: I’m inspired with a new idea, somehow based on this paper, but it’s my own thing.
- ref: This is a reference, or contains a reference that I want to use for something.
- question: or just q: I have a question about this, maybe to ask the author or myself in relation to my data / research.
- quote: I want to quote this, or it contains a useful quote
- note: Not a specific use in mind for this, but it’s worth remembering next time I pick up this paper.
- term: A new term or word I’m not familiar with: I look it up or define it in the annotation.
- crit: I have a criticism of this bit of the paper.
There are a few others I use occasionally, but these are the most common. You probably can think of your own based on how you would categorise the kinds of thoughts that come to you while reading research papers.
Use keywords for each research project/idea
I have 3 or 4 project constantly on the go, and lots of ideas for new projects and papers. I want to capture my responses to what I’m reading in relation to those projects in a reliable way.
So, I have short, unique keywords for each of my projects:
- camedia: a CA project about how people talk about the recording devices they’re using
- cadance: a CA project about partner dance
- thesis: my thesis
- thesis_noticings: my chapter on noticings
- thesis_introduction: get it?
So if I’m reading a paper and it says something like:
“Something I really disagree with and want to comment on or respond to in my next article on dance”
I’ll highlight, copy and paste that into a new annotation, and add a few keywords on the top:
quote: cadance: "Something I really disagree with and want to comment on or respond to in my next article on dance"
This means when I search for all my annotations to do with ‘cadance’ project, I’ll find this one, and I’ll know I wanted to use this as a quote.
Similarly, I may have multiple projects:
quote: cadance: thesis_noticings: "Something I really disagree with and want to comment on or respond to in my next article on dance"
If I want to quote something, but also want to write a note about it, I’ll make two separate annotations on the PDF, one that says:
quote: cadance: thesis_noticings: "Something I really disagree with and want to comment on or respond to in my next article on dance"
The other that says:
note: cadance: thesis_noticings: "Something I really disagree with and want to comment on or respond to in my next article on dance": I really disagree with this for reason, reason and reason.
These will show up in my literature review map as two separate annotations, with different actions attached to them.
Use auto-completion software to make this less painful
I use Switfkey for all my annotation on my Android tablet (where I do most of it). This greatly reduces the time required to type in repetitive tags or keywords that I use all the time to enhance my annotations (see the next section). It also offers auto-complete suggestions so I can remember more complex project keywords / tags easily.
That’s the general advice bit. Geeky advice follows in part II.
So far, this guide has given you some pretty generic advice about note taking, you could use it in any piece of software. The Docear-specific pay-off for this process comes when you import your PDFs into Docear. However, that bit gets pretty geeky. You’ll need to be comfortable with scripting, modifying workflows of existing software packages, and generally be unperturbed by geeky terminology.
If this isn’t your thing, you can just use Docear with the above strategies – or use them more generally in your literature reviewing.
If you are geekily inclined, or just curious, check out part II of this post.
Notes
- ^ One little gotcha: if you’re using a Mac (esp. Yosemite (10.9.X or newer)), you’ll have to do some terminal diddling to make sure you’ve enabled software from unsigned sources to run on your machine or you’ll get an unhelpful error message. Thanks Apple!
Sustainable Research Literature Management with Docear part I Read More »

















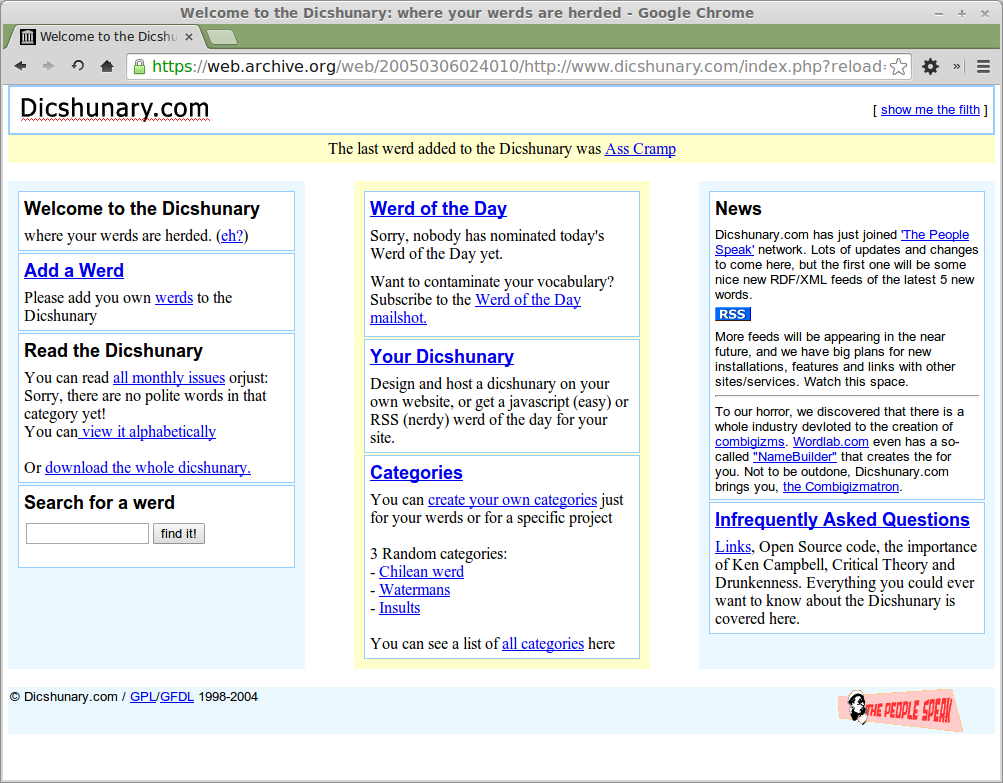
 Installed as a kiosk on recycled computers reclaimed from local skips, dumps and store cupboards, the Dicshunary would capture local place names and micro-dialects from areas near the galleries, schools and public spaces in which it was exhibited.
Installed as a kiosk on recycled computers reclaimed from local skips, dumps and store cupboards, the Dicshunary would capture local place names and micro-dialects from areas near the galleries, schools and public spaces in which it was exhibited.


