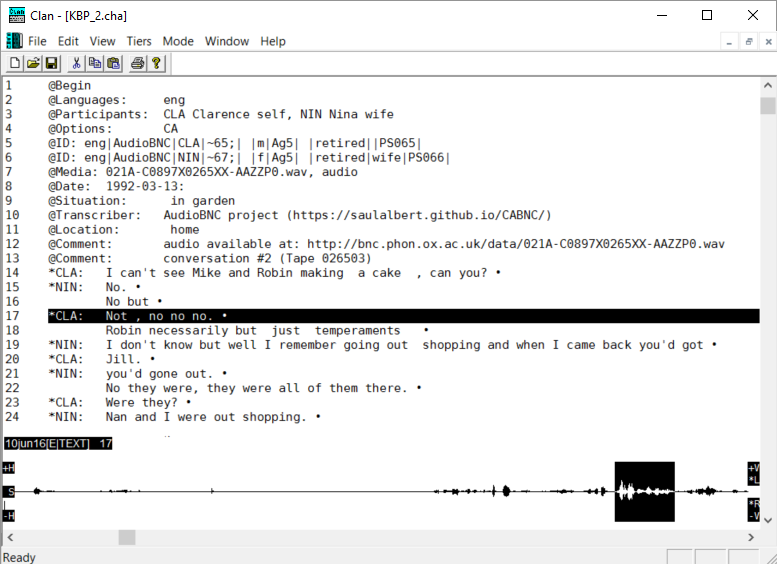
 The CABNC corpus is a open-licensed project to create a detailed conversation analytic (CA) re-transcription of naturalistic conversations from a subcorpus of the British National Corpus amounting to around 4.2 million words in 1436 separate conversations.
The CABNC corpus is a open-licensed project to create a detailed conversation analytic (CA) re-transcription of naturalistic conversations from a subcorpus of the British National Corpus amounting to around 4.2 million words in 1436 separate conversations.
The project aims to produce transcripts usable for both computational linguistics (CL) and detailed qualitative analysis, and invites CA transcribers to use (and re-transcribe) the data, then to re-submit improved transcripts to improve the accuracy of the corpus incrementally over time. The next phase of the project also involves creating a new transcription format: CHAT-CA-lite based on a best-possible compromise between Jeffersonian and the CHILDES project’s machine-readable, XML-transformable CHAT transcription format.
The project has been supported by Bielefeld University, in collaboration with JP de Ruiter and Laura de Ruiter and draws on audio data from the Audio BNC.