There are very few – if any – software tools designed specifically for conversation analytic transcription, partly because so few conversation analysts use them, so there’s not really a ‘market’ for software developers to cater to.
Instead, we have to make do with tools that were designed for more generic research workflows, and which often build in analytic assumptions, constraints and visual metaphors that don’t necessarily correspond with EM/CA’s methodological priorities.
Nonetheless, most researchers that use digital transcription systems choose between two main paradigms.
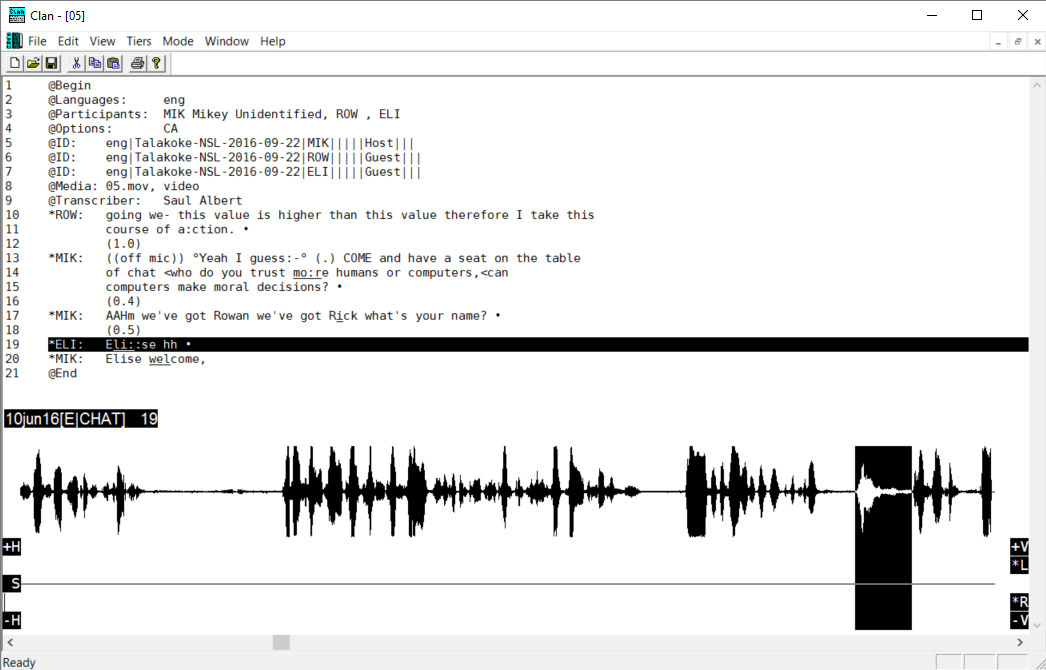
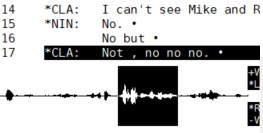
the ‘list-of-turns’-type system represents interaction much like a Jeffersonian transcript: a rendering of turn-by-turn talk, line by line, laid out semi-diagrammatically so that lines of overlapping talk are vertically aligned on the page.
the ‘tiers-of-timelines’ system uses a horizontal scrolling timeline like a video editing interface, with multiple layers or ‘tiers’ representing e.g., each participant’s talk, embodied actions, and other types of action annotated over time.
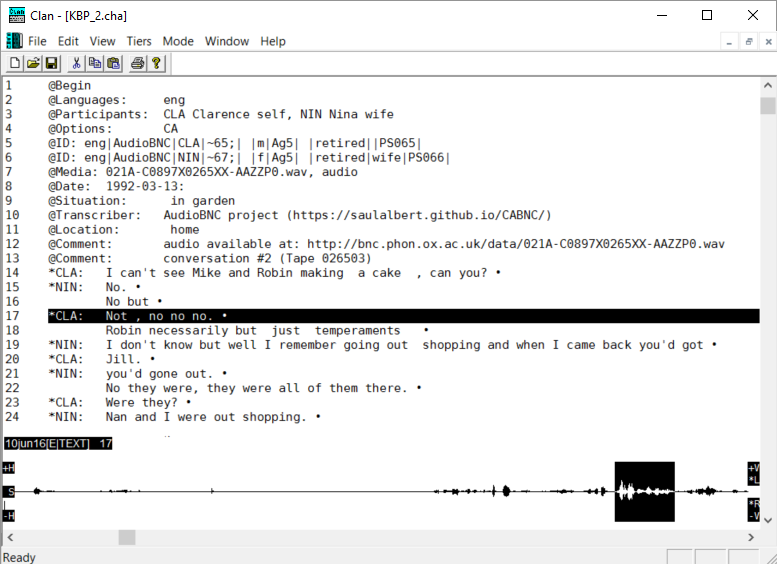
CLAN’s interface (left) and ELAN’s (right) with transcripts of the same bit of audiovisual data
A key utility of both kinds of digital transcription systems is that they allow researchers to align media and transcript, and to use very precise timing tools to check the order and timing of their analytic observations.
For the most part, researchers choose lists-of-turns tools when their analysis is focused on conversation and audible turn-space, and tiers-of-timelines when their analysis focuses on video analysis of visible bodily action.
The problem for EM/CA researchers working with both these approaches, however, is that neither representational schema on its own, (nor any schema save whatever schema may have been constituted through the original interaction itself), is ideal for exploring and describing participants’ sense-making processes and resources.
Tiers-of-timelines representations are great for showing the temporal unfolding of simultaneous action, but it is hard to read more than a few seconds of activity at a glance. By contrast, lists-of-turns use the same basic schema as our well-practiced, mundane reading abilities to scan a page of text and take in the overall structure of a conversation, but reduce the fine-grained timing and multi-activity organization of complex embodied activities.
The reason I put this digital transcription workshop together was to combine existing, well-used software tools for digital transcription from both major paradigms, and to show how to work on a piece of data using both approaches. It’s not intended as a comprehensive ‘solution’, and there are many unresolved practical and conceptual issues, but I think it gives researchers the best chance to address their empirical concerns to help break away from the conceptual and disciplinary constraints that come from analyzing data using one, uniform type of user interface.
The workshop materials include slides (so people can use them to teach collaborators/students) as well as a series of short tutorial videos accompanying each practical exercise in the slides, along with some commentary from me.
My hope is that researchers will use and improve these materials, and possibly extend them to include additional tools (e.g., EXMARaLDA project tools, with which I’m less familiar). If you do, and you find ways to improve them with additional tips, hacks, or updated instructions that take into account new versions, please do let me know.
I tried to make a mix between a film essay and a research presentation of work-in-progress, so it didn’t always work to put references on every slide. I’ve added them below with links to the data used where available.
Abstract
Sacks’ (1963) first published paper on ‘sociological description’ uses the metaphor of a mysterious ‘talking-and-doing’ machine, where researchers from different disciplines come up with incompatible, contradictory descriptions of its functionality. We may soon find ourselves in a similar situation to the one Sacks describes as AI continues to permeate the social sciences, and CA begins to encounter AI either as a research object, as a research tool, or more likely as a pervasive feature of both.
There is now a thriving industry in ‘Conversational AI’ and AI-based tools that claim to emulate or analyse talk, but both the study and use of AI within CA is still unusual. While a growing literature is using CA to study social robotics, voice interfaces, and conversational user experience design (Pelikan & Broth, 2016; Porcheron et al., 2018), few conversation analysts even use digital tools, let alone the statistical and computational methods that underpin conversational AI. Similarly, researchers and developers of conversational AI rarely cite CA research and have only recently become interested in CA as a possible solution to hard problems in natural language processing (NLP). This situation presents an opportunity for mutual engagement between conversational AI and CA (Housley et al., 2019). To prompt a debate on this issue, I will present three projects that combine AI and CA very differently and discusses the implications and possibilities for combined research programmes.
The first project uses a series of single case analyses to explore recordings in which an advanced conversational AI successfully makes appointments over the phone with a human call-taker. The second revisits debates on using automated speech recognition for CA transcription (Moore, 2015) in light of significant recent advances in AI-based speech-to-text, and includes a live demo of ‘Gailbot’, a Jeffersonian automated transcription system. The third project both uses and studies AI in an applied CA context. Using video analysis, it asks how a disabled man and his care worker interact while using AI-based voice interfaces and a co-designed ‘home automation’ system as part of a domestic routine of waking, eating, and personal care. Data are drawn from a corpus of ~500 hours of video data recorded by the participants using a voice-controlled, AI-based ‘smart security camera’ system.
These three examples of CA’s potential interpretations and uses of AI’s ‘talking-and-doing’ machines provide material for a debate about how CA research programmes might conceptualize AI, and use or combine it with CA in a mutually informative way.
Agre, P. (1997). Toward a critical technical practice: Lessons learned in trying to reform AI. Social Science, Technical Systems and Cooperative Work: Beyond the Great Divide. Erlbaum.
Alač, M., Gluzman, Y., Aflatoun, T., Bari, A., Jing, B., & Mozqueda, G. (2020). How Everyday Interactions with Digital Voice Assistants Resist a Return to the Individual. Evental Aesthetics, 9(1), 51.
Berger, I., Viney, R., & Rae, J. P. (2016). Do continuing states of incipient talk exist? Journal of Pragmatics, 91, 29–44. https://doi.org/10.1016/j.pragma.2015.10.009
Bolden, G. B. (2015). Transcribing as Research: “Manual” Transcription and Conversation Analysis. Research on Language and Social Interaction, 48(3), 276–280. https://doi.org/10.1080/08351813.2015.1058603
Brooker, P., Dutton, W., & Mair, M. (2019). The new ghosts in the machine: “Pragmatist” AI and the conceptual perils of anthropomorphic description. Ethnographic Studies, 16, 272–298. https://doi.org/10.5281/zenodo.3459327
Button, Graham. (1990). Going Up a Blind Alley: Conflating Conversation Analysis and Computational Modelling. In P. Luff, N. Gilbert, & D. Frolich (Eds.), Computers and Conversation (pp. 67–90). Academic Press. https://doi.org/10.1016/B978-0-08-050264-9.50009-9
Button, Graham, & Dourish, P. (1996). Technomethodology: Paradoxes and possibilities. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. http://dl.acm.org/citation.cfm?id=238394
Button, G., & Sharrock, W. (1996). Project work: The organisation of collaborative design and development in software engineering. Computer Supported Cooperative Work (CSCW), 5(4), 369–386. https://doi.org/10.1007/BF00136711
Duca, D. (2019). Who’s disrupting transcription in academia? — SAGE Ocean | Big Data, New Tech, Social Science. SAGE Ocean. https://ocean.sagepub.com/blog/whos-disrupting-transcription-in-academia
Fischer, J. E., Reeves, S., Porcheron, M., & Sikveland, R. O. (2019). Progressivity for voice interface design. Proceedings of the 1st International Conference on Conversational User Interfaces – CUI ’19, 1–8. https://doi.org/10.1145/3342775.3342788
Garfinkel, H. (1967). Studies in ethnomethodology. Prentice-Hall.
Goodwin, C. (1996). Transparent vision. In E. A. Schegloff & S. A. Thompson (Eds.), Interaction and Grammar (pp. 370–404). Cambridge University Press.
Heath, C., & Luff, P. (1992). Collaboration and control: Crisis management and multimedia technology in London Underground Line Control Rooms. Computer Supported Cooperative Work (CSCW), 1(1–2), 69–94.
Heritage, J. (1984). Garfinkel and ethnomethodology. Polity Press.
Heritage, J. (1988). Explanations as accounts: A conversation analytic perspective. In C. Antaki (Ed.), Analysing Everyday Explanation: A Casebook of Methods (pp. 127–144). Sage Publications.
Hoey, E. M. (2017). Lapse organization in interaction [PhD Thesis, Max Planck Institute for Psycholinguistics, Radbound University, Nijmegen]. http://bit.ly/hoey2017
Housley, W., Albert, S., & Stokoe, E. (2019). Natural Action Processing. In J. E. Fischer, S. Martindale, M. Porcheron, S. Reeves, & J. Spence (Eds.), Proceedings of the Halfway to the Future Symposium 2019 (pp. 1–4). Association for Computing Machinery. https://doi.org/10.1145/3363384.3363478
Kendrick, K. H. (2017). Using Conversation Analysis in the Lab. Research on Language and Social Interaction, 50(1), 1–11. https://doi.org/10.1080/08351813.2017.1267911
Leviathan, Y., & Matias, Y. (2018). Google Duplex: An AI System for Accomplishing Real-World Tasks Over the Phone [Blog]. Google AI Blog. http://ai.googleblog.com/2018/05/duplex-ai-system-for-natural-conversation.html
Local, J., & Walker, G. (2005). Methodological Imperatives for Investigating the Phonetic Organization and Phonological Structures of Spontaneous Speech. Phonetica, 62(2–4), 120–130. https://doi.org/10.1159/000090093
Luff, P., Gilbert, N., & Frolich, D. (Eds.). (1990). Computers and Conversation. Academic Press.
Moore, R. J. (2015). Automated Transcription and Conversation Analysis. Research on Language and Social Interaction, 48(3), 253–270. https://doi.org/10.1080/08351813.2015.1058600
Ogden, R. (2015). Data Always Invite Us to Listen Again: Arguments for Mixing Our Methods. Research on Language and Social Interaction, 48(3), 271–275. https://doi.org/10.1080/08351813.2015.1058601
O’Leary, D. E. (2019). Google’s Duplex: Pretending to be human. Intelligent Systems in Accounting, Finance and Management, 26(1), 46–53. https://doi.org/10.1002/isaf.1443
Pelikan, H. R. M., & Broth, M. (2016). Why That Nao? Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems – CHI \textquotesingle16. https://doi.org/10.1145/2858036.2858478
Pelikan, H. R. M., Broth, M., & Keevallik, L. (2020). “Are You Sad, Cozmo?”: How Humans Make Sense of a Home Robot’s Emotion Displays. Proceedings of the 2020 ACM/IEEE International Conference on Human-Robot Interaction, 461–470. https://doi.org/10.1145/3319502.3374814
Porcheron, M., Fischer, J. E., Reeves, S., & Sharples, S. (2018). Voice Interfaces in Everyday Life. Proceedings of the 2018 ACM Conference on Human Factors in Computing Systems (CHI’18).
Reeves, S. (2017). Some conversational challenges of talking with machines. Talking with Conversational Agents in Collaborative Action, Workshop at the 20th ACM Conference on Computer-Supported Cooperative Work and Social Computing. http://eprints.nottingham.ac.uk/40510/
Relieu, M., Sahin, M., & Francillon, A. (2019). Lenny the bot as a resource for sequential analysis: Exploring the treatment of Next Turn Repair Initiation in the beginnings of unsolicited calls. https://doi.org/10.18420/muc2019-ws-645
Robles, J. S., DiDomenico, S., & Raclaw, J. (2018). Doing being an ordinary technology and social media user. Language & Communication, 60, 150–167. https://doi.org/10.1016/j.langcom.2018.03.002
Sacks, H. (1984). On doing “being ordinary.” In J. Heritage & J. M. Atkinson (Eds.), Structures of social action: Studies in conversation analysis (pp. 413–429). Cambridge University Press.
Sacks, H. (1987). On the preferences for agreement and contiguity in sequences in conversation. In G Button & J. R. Lee (Eds.), Talk and social organization (pp. 54–69). Multilingual Matters.
Sacks, H. (1995a). Lectures on conversation: Vol. II (G. Jefferson, Ed.). Wiley-Blackwell.
Sacks, H., Schegloff, E. A., & Jefferson, G. (1974). A simplest systematics for the organization of turn-taking for conversation. Language, 50(4), 696–735. https://doi.org/10.2307/412243
Sahin, M., Relieu, M., & Francillon, A. (2017). Using chatbots against voice spam: Analyzing Lenny’s effectiveness. Proceedings of the Thirteenth Symposium on Usable Privacy and Security, 319–337.
Schegloff, E. A. (1988). On an Actual Virtual Servo-Mechanism for Guessing Bad News: A Single Case Conjecture. Social Problems, 35(4), 442–457. https://doi.org/10.2307/800596
Schegloff, E. A. (1993). Reflections on Quantification in the Study of Conversation. Research on Language & Social Interaction, 26(1), 99–128. https://doi.org/10.1207/s15327973rlsi2601_5
Schegloff, E. A. (2004). Answering the Phone. In G. H. Lerner (Ed.), Conversation Analysis: Studies from the First Generation (pp. 63–109). John Benjamins Publishing Company.
Schegloff, E. A. (2010). Some Other “Uh(m)s.” Discourse Processes, 47(2), 130–174. https://doi.org/10.1080/01638530903223380
Soltau, H., Saon, G., & Kingsbury, B. (2010). The IBM Attila speech recognition toolkit. 2010 IEEE Spoken Language Technology Workshop, 97–102. https://doi.org/10.1109/SLT.2010.5700829
Stivers, T. (2015). Coding Social Interaction: A Heretical Approach in Conversation Analysis? Research on Language and Social Interaction, 48(1), 1–19. https://doi.org/10.1080/08351813.2015.993837
Stokoe, E. (2011). Simulated Interaction and Communication Skills Training: The `Conversation-Analytic Role-Play Method’. In Applied Conversation Analysis (pp. 119–139). Palgrave Macmillan UK. https://doi.org/10.1057/9780230316874_7
Stokoe, E. (2013). The (In)Authenticity of Simulated Talk: Comparing Role-Played and Actual Interaction and the Implications for Communication Training. Research on Language & Social Interaction, 46(2), 165–185. https://doi.org/10.1080/08351813.2013.780341
Stokoe, E. (2014). The Conversation Analytic Role-play Method (CARM): A Method for Training Communication Skills as an Alternative to Simulated Role-play. Research on Language and Social Interaction, 47(3), 255–265. https://doi.org/10.1080/08351813.2014.925663
Stokoe, E., Sikveland, R. O., Albert, S., Hamann, M., & Housley, W. (2020). Can humans simulate talking like other humans? Comparing simulated clients to real customers in service inquiries. Discourse Studies, 22(1), 87–109. https://doi.org/10.1177/1461445619887537
Turing, A. (1950). Computing machinery and intelligence. Mind, 49, 433–460.
Walker, G. (2017). Pitch and the Projection of More Talk. Research on Language and Social Interaction, 50(2), 206–225. https://doi.org/10.1080/08351813.2017.1301310
Wong, J. C. (2019, May 29). “A white-collar sweatshop”: Google Assistant contractors allege wage theft. The Guardian. https://www.theguardian.com/technology/2019/may/28/a-white-collar-sweatshop-google-assistant-contractors-allege-wage-theft
AI and voice technologies in disability and social care
There is a crisis in social care for disabled people, and care providers are turning to AI for high-tech solutions. However, research often focuses on medical interventions rather than on how disabled people adapt technologies and work with their carers to enhance their independence.
This project explores how disabled people adapt consumer voice technologies such as the Amazon Alexa to enhance their personal independence, and the wider opportunities and risks that AI-based voice technologies may present for future social care services.
We are using a Social Action research method to involve disabled people and carers in shaping the research from the outset, and conversation analysis to examine how participants work together using technology (in the broadest sense – including language and social interaction), to solve everyday access issues.
Voice technologies are often marketed as enabling people’s independence.
For example, a 2019 Amazon ad entitled “Morning Ritual” features a young woman with a visual impairment waking up, making coffee, then standing in front of a rain-spattered window while asking Alexa what the weather is like.
Many such adverts, policy reports and human-computer interaction studies suggest that new technologies and the ‘Internet of Things’ will help disabled people gain independence. However, technology-centred approaches often take a medicalized approach to ‘fixing’ individual disabled people, which can stigmatize disabled people by presenting them as ‘broken’, offering high-tech, lab-based solutions over more realistic adaptations.
This project explores how voice technologies are used and understood by elderly and disabled people and their carers in practice. We will use applied conversation analysis – a method designed to show, in procedural detail, how people achieve routine tasks together via language and social interaction.
A simple example: turning off a heater
Here’s a simple example of the kind of process we are interested in.
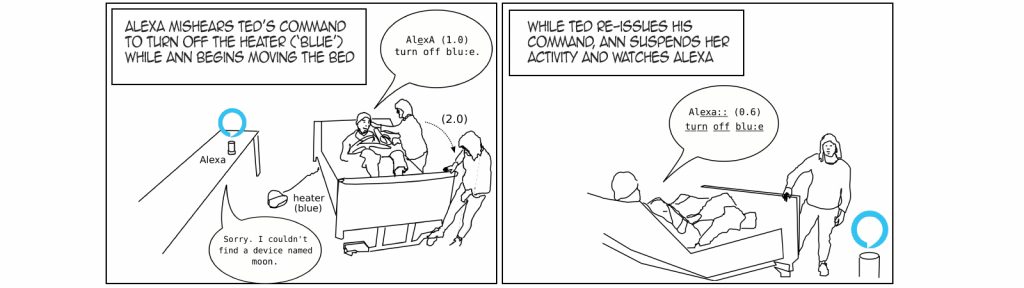
In the illustration below, Ted, who is about to be hosted out of his bed, gives a command to Alexa to turn off his heater (named ‘blue’) while his carer, Ann moves around his bed, unclipping the wheel locks so she can move it underneath the hoist’s ceiling track. Before Ann can move the bed, she has to put away the heater. Before she can put it away, it must be switched off.
Ann leaves time and space for Ted to use Alexa to participate in their shared activity.
While Ann could easily have switched off the heater herself before moving it out of the way and starting to push the bed towards the hoist, she pauses her activity while Ted re-does his command to Alexa – this time successfully. You can see this sequence of events as it unfolds in the video below.
Here are a few initial observations we can make about this interaction.
Firstly, Ann is clearly working with Ted, waiting for him to finish his part of the collaborative task before continuing with hers. By pausing her action, she supports the independence of his part of their interdependent activity.
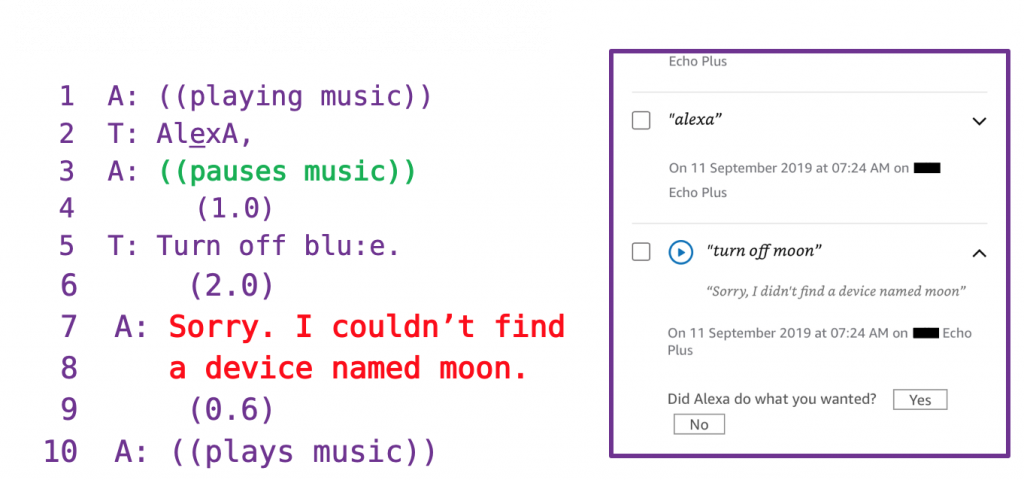
Secondly, using conversation analytic transcriptions and the automated activity log of the Amazon device, we can study the sequences of events that lead up to such coordination problems. For example, we can see that when Ted says the ‘wake word’ Alexa, it successfully pauses the music and waits for a command. We can see how Alexa mishears the reference to the heater name ‘blue’, then in lines 7 and 8, it apologizes and gives an account for simply giving up on fulfilling the request and unpausing the music.
Alexa mishears Ted’s reference to the heater ‘blue’, then terminates the request sequence
These moments give us insight both into the conversation design of voice and home automation systems, and also into how interactional practices and jointly coordinated care activities can support people’s independence.
Albert, S., Albury, C., Alexander, M., Harris, M. T., Hofstetter, E., B., E. J., & Stokoe, E. (2018). The conversational rollercoaster: Conversation analysis and the public science of talk. Discourse Studies, 20(3), 397–424. https://doi.org/10.1177/1461445618754571
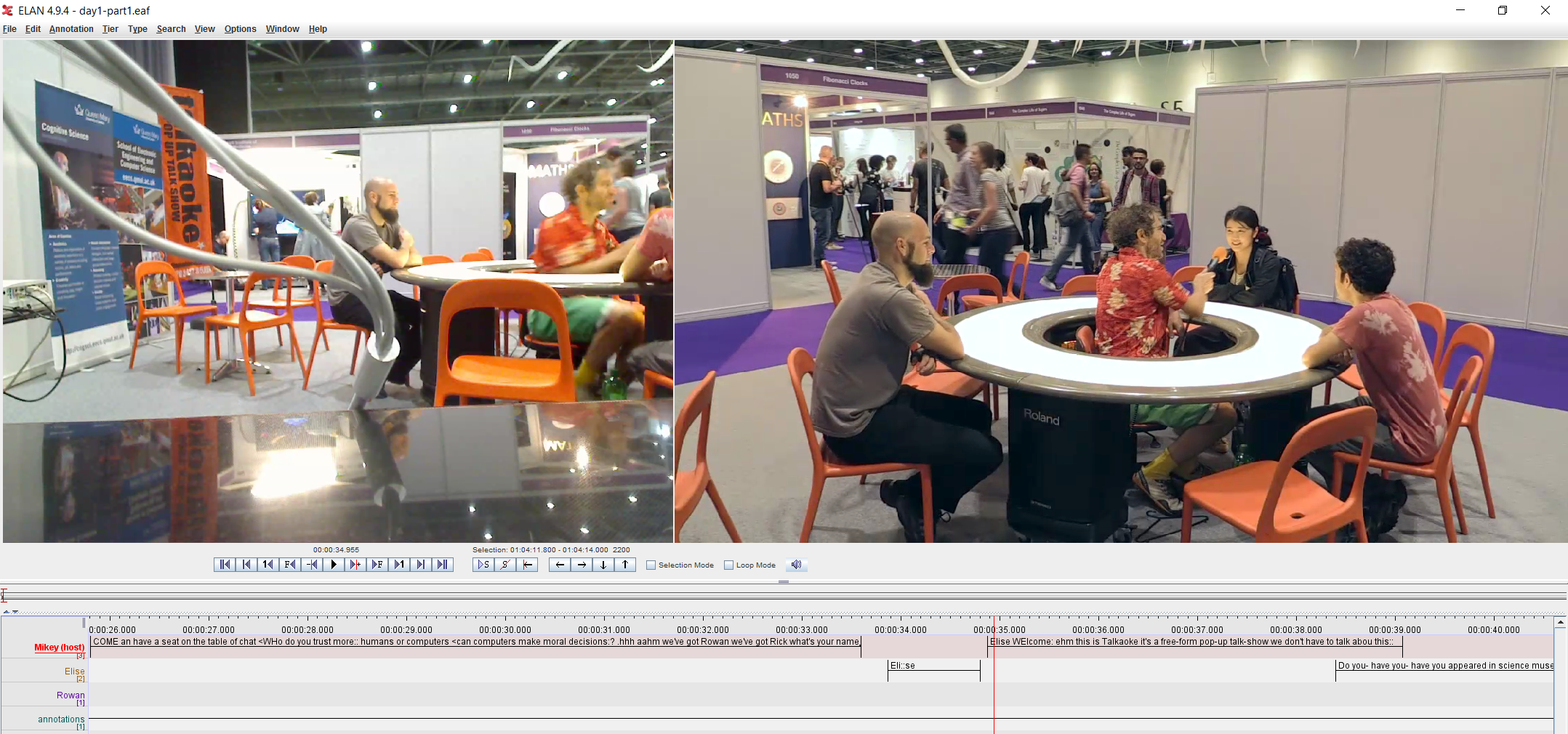
The Conversational Rollercoaster is a new public ‘demo’ format for ethnomethodology and conversation analysis. I developed the format for New Scientist Live in collaboration with Loughborough and the CARM group in order to make it easier to explain EM/CA research in a public exhibition context. The idea is that you can take a live conversation – in this case provided by The People Speak‘s pop-up talk-show Talkaoke, and subject it to instant EM/CA analysis. What’s more, you can involve the public as analysts in a variety of activities – ‘being the data’ on the Talkaoke table, spotting interactional phenomena, gathering data, transcribing, analyzing and reporting findings on the ‘results wall’.
Ann Doehring‘s very nice drawing of the process (in the tweet above) provides a useful outline of how it works – and how it can be adapted for other contexts. All the software, data, photos and other materials are available for re-use and re-development.
A full how-to blog post for those wishing to try running the format themselves will soon be available on my blog. Until then, check the blog post at https://rolsi.net/ for a description of the event.
Thanks to:
The CogSci group at Queen Mary University of London, especially Ella Rice and the whole team at EECS.
The CABNC corpus is a open-licensed project to create a detailed conversation analytic (CA) re-transcription of naturalistic conversations from a subcorpus of the British National Corpus amounting to around 4.2 million words in 1436 separate conversations.
The project aims to produce transcripts usable for both computational linguistics (CL) and detailed qualitative analysis, and invites CA transcribers to use (and re-transcribe) the data, then to re-submit improved transcripts to improve the accuracy of the corpus incrementally over time. The next phase of the project also involves creating a new transcription format: CHAT-CA-lite based on a best-possible compromise between Jeffersonian and the CHILDES project’s machine-readable, XML-transformable CHAT transcription format.
Dances – like everyday physical interactions – are built from a constrained repertoire of possible bodily movements. It’s a useful activity to study because the performers, learners and audiences of dance can be observed managing the production and evaluation of movements specifically as dance.
A Figure from a forthcoming paper on timing and balance in novice partner dancers. The figure compares how Jim (in green) falls over after ending a move in a teetering position with how Paul (in fuchsia) has a more balanced stance.
This presents participants with interesting and observable challenges. How do they move from dancing to non-dancing, and how do they show each other that they are making these switches? How do audiences decide when and how to applaud, and how do they demonstrate their sensitivity to particular parameters and relevant moments of evaluation during a dance? And what is distinctive about bodily movement that makes it function as dance?
This research forms part of an overall exploration of social/aesthetic practices and activities including learning, teaching, and performing dance, and body-oriented psychotherapies that involve people in doing and evaluating of dance movements. For example, Dirk vom Lehn and I have collected a large amount of video showing how novice partner dancers learn during workshops, and have been analyzing these alongside video of professional improvised dance performances.
Publications
Albert, S., & vom Lehn, D. (2023). Non-lexical vocalizations help novices learn joint embodied actions. Language & Communication, 88, 1–13. https://doi.org/10.1016/j.langcom.2022.10.001
Albert, S., & vom Lehn, D. (2018, August). The First Step is Always the Hardest: Rhythm and Methods of Mutual Coordination between Novice Dancers. 113th American Sociological Association Annual Meeting, Philadelphia, PA.
vom Lehn, D. & Albert, S. (2018, July). Producing ‘joint action’ in Lindy Hop Dance Lessons. Annual Meeting of the Society for the Study of Symbolic Interaction 2018, Lancaster, UK.
Albert, S. (2015, June). Dancing through time and space. Paper presented at Revisiting Participation: Language and Bodies in Interaction, Basel.
Albert, S. (2014, June). Interactional resources and their use in learning the Lindy Hop. Paper presented at the 6th Ethnography and Qualitative Research Conference, Bergamo.
Albert, S. (2014, June). Interactional choreography. Paper presented at the 1st EMCA Doctoral Network Meeting, Edinburgh.
A wiki and collaborative bibliography on Ethnomethodology and Conversation Analysis.
EMCA wiki screenshot
The EMCA wiki is an information resource and comprehensive bibliography built by and for the Ethnomethodology and Conversation Analysis research community.
In October 2014 Paul ten Have stepped down as the sole maintainer of the vast EMCA news bibliography and website he had been updating weekly since 1996. The EMCAwiki continues that legacy, aiming to develop it into an ongoing resource.
The site is run by a group of volunteer admins and contributors, and will be supported and managed by the International Society of Conversation Analysis from September 2015.
Contributors and admins on the initial version include Paul ten Have himself, Elliott Hoey, Edward Holmes, Mea Popoviciu, Joshua Raclaw, Clair-Antoine Veyrier.
We walked the streets looking for people listening to headphones then talked to them about the music, their day, and the location while recording whatever they happened to be listening to. The result was a show that offered a glimpse into people’s soundtracks to the city, and how they used them to move through their day.
Host Mikey and postman Kwame in Brixton
Traffic Island Disks started out with a regular slot on London’s Resonance FM station in 2003, then grew into an internationally touring live Internet radio show. In 2004 we designed a mobile system with custom software for live mixing, editing and streaming, and teamed up with local presenters to stream the show via wifi connection from the streets of cities starting in Newcastle then touring to Bratislava, Vienna, Sofia, Aarhus and San Jose.
Enables large groups of passers-by to engage in ongoing spontaneous conversations.
Heckle used in the foyer of the National Theatre
Heckle augments conversations by letting people catch up with what is being talked about visually – providing a user-contributed flow of relevant texts, tweets images, videos, websites overlaid on a live video feed of the event.
Developed with The People Speak to augment their public conversational performances, Heckle lets participants use a web app to contribute to a live visual summary of the conversation so far, so that new people can get involved at any time in the course of a discussion.
Heckle also provides a post-event visual timeline of the conversation, so over the last 7 years, The People Speak have been building a searchable, participant-annotated video archive of spontaneous conversations.
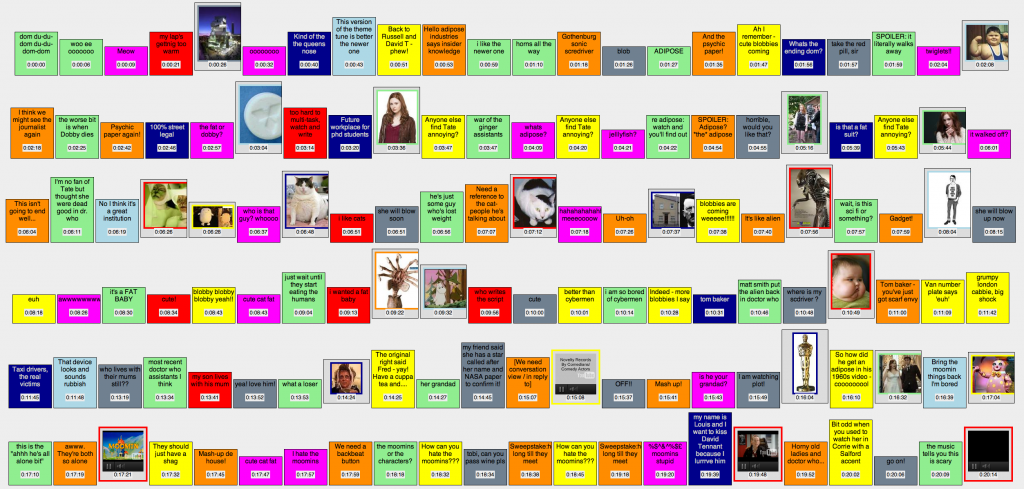
Heckling at Ontologies explored the relationship between TV-viewers’ text chat and TV broadcaster media metadata.
Heckling at Ontologies Research Poster
Heckling at Ontologies is a collaboration with fellow MAT student Toby Harris exploring the dissonance between top-down and bottom-up approaches to media metadata generation. The project started with two datasets:
1. A semantic description of Season 4, Episode 1 of Doctor Who
2. User-generated tweets ‘heckled’ at the screen by viewers
As part of an industrial placement at BT, I worked with The People Speak to develop a new version of Heckle, a web service that gathers tweets, images, videos and texts ‘heckled’ to a shared screen by viewers of a TV show, building up a visual summary of the mediated conversation. These two data sets were analysed to discover the dissonances and regularities between Toby’s top-down and my bottom-up descriptions of the same TV show.
The two data sets were then superimposed on a live stream of the video. You can download the source of the demo and grab copies of semantic data on the ontoheckle github page.
Thanks to all the participants in the Dr. Who screenings, Richard Kelly, and The People Speak.
This research was funded by the Digital Economy programme through the Media and Arts Technology Doctoral Training Centre at Queen Mary, University of London