I have put my introduction to digital transcription workshop materials and tutorials online, here’s a little blog outlining some of the reasons I started developing the workshop, and how I hope researchers will use it.
There are very few – if any – software tools designed specifically for conversation analytic transcription, partly because so few conversation analysts use them, so there’s not really a ‘market’ for software developers to cater to.
Instead, we have to make do with tools that were designed for more generic research workflows, and which often build in analytic assumptions, constraints and visual metaphors that don’t necessarily correspond with EM/CA’s methodological priorities.
Nonetheless, most researchers that use digital transcription systems choose between two main paradigms.
- the ‘list-of-turns’-type system represents interaction much like a Jeffersonian transcript: a rendering of turn-by-turn talk, line by line, laid out semi-diagrammatically so that lines of overlapping talk are vertically aligned on the page.
- the ‘tiers-of-timelines’ system uses a horizontal scrolling timeline like a video editing interface, with multiple layers or ‘tiers’ representing e.g., each participant’s talk, embodied actions, and other types of action annotated over time.
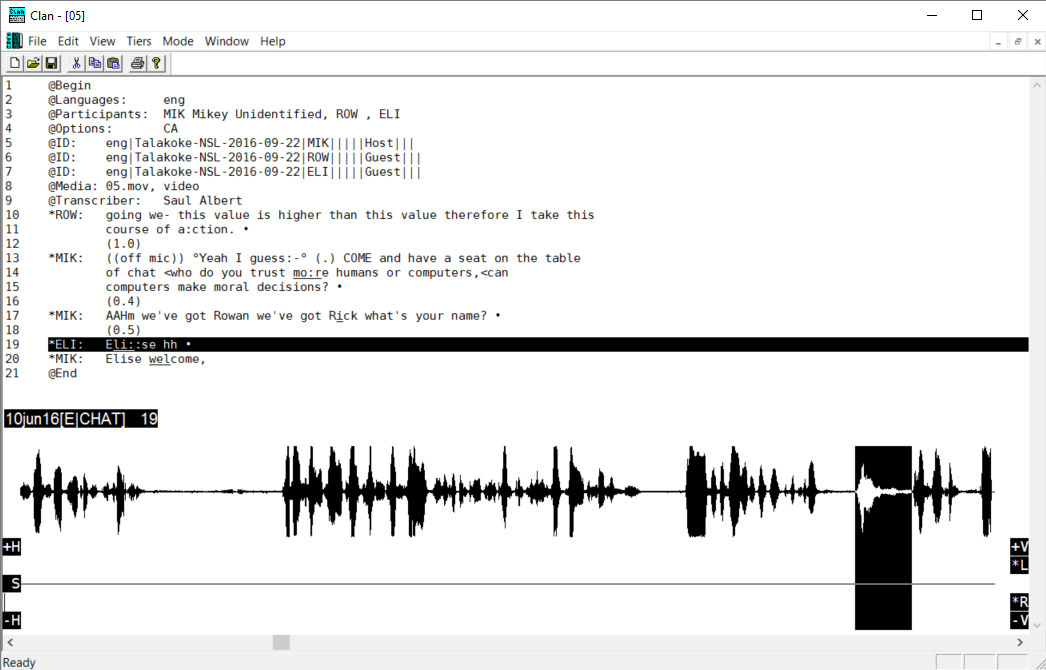
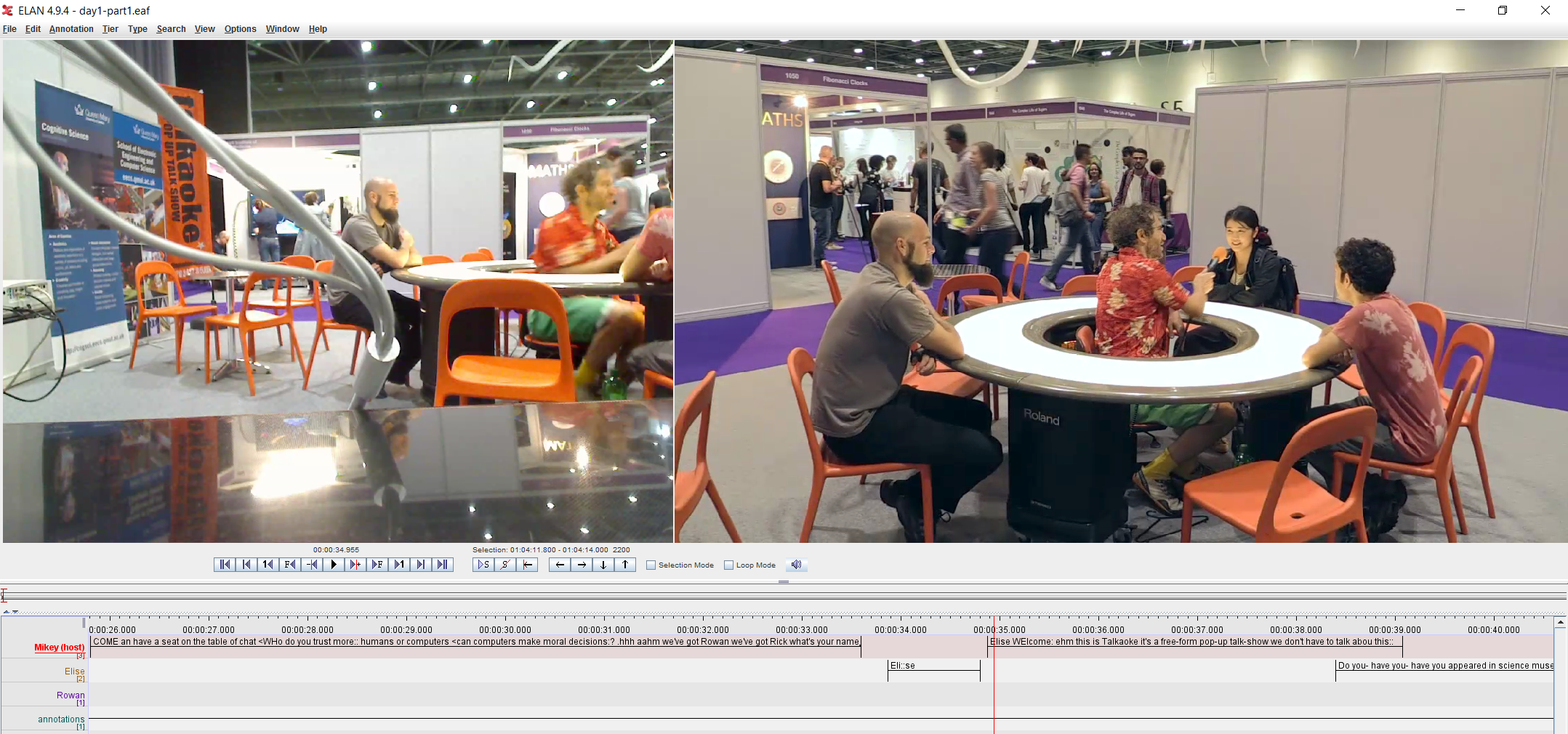
A key utility of both kinds of digital transcription systems is that they allow researchers to align media and transcript, and to use very precise timing tools to check the order and timing of their analytic observations.
I used these terms to describe this distinction between representational schema in a short ‘expert box’ for Alexa Hepburn and Galina Bolden’s excellent (2017) book Transcribing for Social Research entitled “how to choose transcription software for conversation analysis“, where I tried to explain what is at stake in choosing one or the other type of system .
For the most part, researchers choose lists-of-turns tools when their analysis is focused on conversation and audible turn-space, and tiers-of-timelines when their analysis focuses on video analysis of visible bodily action.
The problem for EM/CA researchers working with both these approaches, however, is that neither representational schema on its own, (nor any schema save whatever schema may have been constituted through the original interaction itself), is ideal for exploring and describing participants’ sense-making processes and resources.
Tiers-of-timelines representations are great for showing the temporal unfolding of simultaneous action, but it is hard to read more than a few seconds of activity at a glance. By contrast, lists-of-turns use the same basic schema as our well-practiced, mundane reading abilities to scan a page of text and take in the overall structure of a conversation, but reduce the fine-grained timing and multi-activity organization of complex embodied activities.
In any case, neither of these representational schema, nor any currently available transcription tools adequately capture the dynamics of movement in the way that, for example, specialized graphical methods and life drawing techniques were developed to achieve (although our Drawing Interactions prototype points to some possibilities).
The reason I put this digital transcription workshop together was to combine existing, well-used software tools for digital transcription from both major paradigms, and to show how to work on a piece of data using both approaches. It’s not intended as a comprehensive ‘solution’, and there are many unresolved practical and conceptual issues, but I think it gives researchers the best chance to address their empirical concerns to help break away from the conceptual and disciplinary constraints that come from analyzing data using one, uniform type of user interface.
The workshop materials include slides (so people can use them to teach collaborators/students) as well as a series of short tutorial videos accompanying each practical exercise in the slides, along with some commentary from me.
My hope is that researchers will use and improve these materials, and possibly extend them to include additional tools (e.g., EXMARaLDA project tools, with which I’m less familiar). If you do, and you find ways to improve them with additional tips, hacks, or updated instructions that take into account new versions, please do let me know.
Update: there is now DOTE: one of the first bits of software designed specifically for digital EM/CA transcription – and it’s amazing! https://www.dote.aau.dk/