NB: There is an updated version of this post.
Problem
There are great software tools out there for CA-style transcription, my favourite is CLAN for a number of reasons. However, I can’t find any resources online about how to publish CA-style transcriptions without being forced through some eye-bleeding LaTeX diddling every time.
Of course I could just use a WYSIWYG text editor like LibreOffice – but now I’ve experienced the power of LaTeX for document preparation and publication, I really can’t see myself going back.
When doing CA it seems particularly important to have transcriptions legibly in the body of the paper and visible during the writing process, because many of the analytical observations come, or get significantly modified at the point of writing about them, double and triple checking assumptions, and cross-referencing with the CA literature while tweaking citations.
My chosen solution: Markdown + Pandoc
Markdown is my favourite lightweight markup language, a highly readable format with which you can write a visually pleasing text file, which you can then convert into almost any other format – HTML, OpenOffice, LaTeX, RTF, etc. using Pandoc. There are many similar systems, notably reStructuredText and Textile, all of which you can use to write your text file, and other conversion tools/toolsets, but in my experience, Markdown and Pandoc are the most useful combination in an academic context 1.
There are lots of great things about markdown:
- Just edit simple text files – no weird file formats to get corrupted or mangled.
- Less verbose and complicated-looking than LaTeX.
- Small files are easy to share/collaborate on with others (everyone gets to use their favourite editor).
- There are some great pandoc plugins for my favourite text editor vim.
However, the best thing is that, used along with the XeTeX typesetting engine, it solves the problem with CA transcriptions being unreadable in LaTeX/pdflatex.
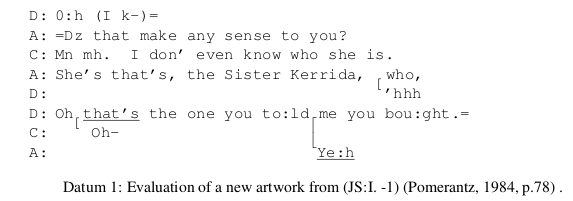
For example, in my first CA-laced paper, my transcriptions looked like this in my LaTeX source:
\begin{table*}[!ht]
\hfill{}
\texttt{
\begin{tabular}{@{}p{2mm}p{2mm}p{150mm}@{}}
& D: & 0:h (I k-)= \\
& A: & =Dz that make any sense to you? \\
& C: & Mn mh. I don' even know who she is. \\
& A: & She's that's, the Sister Kerrida, \hspace{.3mm} who, \\
& D: & \hspace{76mm}\raisebox{0pt}[0pt][0pt]{ \raisebox{2.5mm}{[}}'hhh \\
& D: & Oh \underline{that's} the one you to:ld me you bou:ght.= \\
& C: & \hspace{2mm}\raisebox{0pt}[0pt][0pt]{ \raisebox{2.5mm}{[}} Oh-- \hspace{42mm}\raisebox{0pt}[0pt][0pt]{ \raisebox{2mm}{\lceil}} \\
& A: & \hspace{60.2mm}\raisebox{0pt}[0pt][0pt]{ \raisebox{3.1mm}{\lfloor}}\underline{Ye:h} \\
\end{tabular}
\hfill{}
}
\caption{ Evaluation of a new artwork from (JS:I. -1) \cite[p.78]{Pomerantz1984} .}
\label{ohprefix}
\end{table*}
which renders this:
In Markdown for my latest paper, the CA bits look like this:
(3)
STE: U̲o̲:̲h̲ oh ugly things [he paints.]
KAT: [Really?]
(3.0)
STE: (°I think s[o-])°
KAT: [So you wouldn't sell any?]
STE: U̲u̲h̲ n[o]
KAT: [No?]
(1.7)
which renders this:

There is a small amount of control sacrificed here – possibly for unicode XeTeX or font issues – I’m not sure yet – I don’t get to render the nicely stretched ceiling characters for overlap marking, or the raised full stop / bullet operator for inbreaths, but normal full stops and square brackets work reasonably well.
Overall, I think the Markdown version represents a significant improvement in legibility. I think it might be possible to do the same in LaTeX using the {verbatim} environment, but the fact that Markdown also lets me concentrate on writing without throwing errors or refusing to compile lets me spend longer on the writing than on endless text-fiddling procrastination.
When it comes to rendering, I feed my markdown file to pandoc:
$ pandoc --latex-engine xelatex --bibliography library.bib --csl default.csl -N -o paper_title.pdf paper_title.markdown
I use a citation style language file to customise how my bibliographical references are rendered, and it pops out looking like I slaved over the LaTeX for hours.
I came on your website through a google search. I am considering markdown but one of the issues I wanted to tackle first is to see if it is possible to format my conversations nicely in an easy way. You seem to have nailed this.
You state in markdown I write X which renders the image you have provided. However, I don’t really *see* what you write in markdown. If I copy the text you use it just becomes one long sentence. Probably there are some hidden things that I don’t copy? How do you create the space between ‘STE:’ and ‘Uo:h’ for instance? and how do you make sure it is the same distance as with the other names and their texts? (especially when you use different names and the names are not equally long).
Thanks in advance!
Hi there,
I see your point – I wasn’t very clear about how I do this in detail, and I modified my workflow somewhat and kept meaning to write it up…
I started writing you a comment response – it got too long, so I wrote a new and expanded version of this blog post, and created a set of demo files that should help get you started.
Happy pandoccing!
Oh, and to answer your question directly, there is a far simpler way of doing all this: just use four spaces before each line of your transcript in your Markdown file – that means Pandoc should read it as preformatted text, and just print it like it sees it (no linebreaks etc.)
Thanks for your detailed new blogpost! I will look into it.
I figured out the 4 spaces thing already, but then I write in another font than I want it to be formatted in the end, so that wouldn’t be an ideal situation (though I definitely could work with that).
I’m not really sure I understand your issue – but if you check the updated blog post it shows you by example how to choose which font you want to use to render your monospace (verbatim) font bits.